Mark Join — Unnesting Query
TPC-DS 中包含一个特殊的 Nested Query,虽然子查询的位置出现在 where 中,但其无法通过 Semi Join 改写实现。出于好奇,我查询了其他系统对这类子查询的实现方式,在此分享给大家。
背景
SQL-99 允许 nested subqueries 出现在 query 的各个位置,包括 select ,where 等等。为了保证这些复杂的 query 可以被有效快速的执行,针对不同的 nested 位置,以及是否 correlated 来进行不同的 unnested 处理,从而提升查询效率。 本文主要讲述的是一种出现在 where 子句中的 nested subqueries 的 unnesting 实现方式。
名词解释
- query: 查询,本文中主要指代 SQL 查询语句
- nested subquery:嵌套子查询,指出现在 query 中的子查询,比如 where r.a in ( subquery)。
- correlated: 关联子查询,指的是子查询中带有和外层列相关的条件。
- unnested subquery:非嵌套子查询,通过合理的代数转换,将带嵌套子查询的 query 通过规划改写等方式解嵌套成,正常的非嵌套子查询的 query。
- disjunction:由 or 链接的两个谓词之间的关系就是 disjunction。比如 a.k1=1 or b.k1=1。
Mark Join
为什么会产生 Mark Join
子查询中一类不寻常的由 exists(not exists etc.) 和 unique, quantified comparisons 产生的谓词子查询。简单说就是一个 query,他的where 条件既包含 exists 类的子查询,也包含量化普通谓词,并且其之间的关系还是 disjunction。例如:exists 子句 + or + in predicate
select l_orderkey
from lineitem
where exists (select * from orders
where o_orderkey = l_orderkey)
or l_linenumber in (1,2,3);看到 exists 通常我们会将其改写为 Semi Join 从而达到 unnested 的效果,但是这个查询不行,因为 exists 出现在一个 disjunction 中。也就是说,即使 lineitem 没有对应的 order, 也有可能被输出,因此我们不能使用 Semi Join。
Mark Join 是什么
上面的查询不能直接改写成为 Semi Join 的最主要原因就是:Semi Join 会提前过滤不满足 join 条件的行,使得哪些本可以满足 l_linenumber in (1,2,3) 的行被提前过滤,从而导致结果不正确。
这时候 Mark Join 就产生了。Mark Join 也会进行正常的 join 匹配,但他不会直接过滤掉不满足 join 条件的行。而是通过产生一个新的列 marker 用于标记是否行是否满足 join 条件。Mark Join 的公式如下,其中 P 为 T1 表和 T2 表之间的 Join 条件,m 则为标记列。
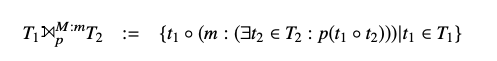
那么使用 Mark Join 后,刚才的查询就可以转换成一个正常的关系 Join Query 了。首先,括号中先对 linetime 表和 orders 表根据刚才的条件 o_orderkey = l_orderkey 进行类似 Semi Join 的操作,并将是否能匹配到的结果存储在 m 列中。最后在对 Mark Join 后的结果进行过滤,满足 l_linenumber 在 (1,2,3) 或者 m 列为 true 的都会输出。
Mark Join 是如何处理 nested subquery 的
让我们来看一下上述 nested subquery 在使用了 mark join 后的 Query plan :
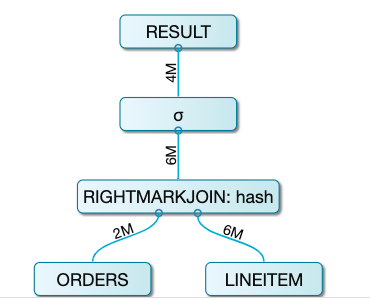
step1:mark join 阶段
自底向上看,首先是对 orders 和 lineitem 这两张表进行了 Mark Join。也就是说对右表 lineitem 表进行 mark 操作。
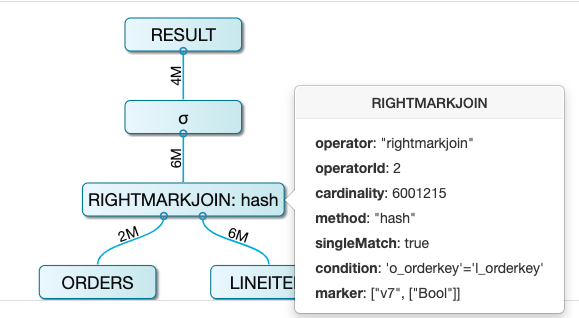
点开详情可以看到,Mark Join 的 join 条件是 o_orderkey = l_orderkey,新生成的列 v7 列是 marker 列。这列的类型是 bool。当 tuple 满足 join 条件的时候,marker 列会设置为 True,如果不满足条件则设置为 False。(其实还有一种取值是 Null, 这个我们后面再说)。此时,经过 Mark Join 输出的 Tuple 类似于:

lineitem 中的行均被保留,只不过多了一个 v7 列,用于存储是否能匹配上 orders 表。当 l_orderkey = 1 时,由于 orders 表中也存在一个 o_orderkey =1 则匹配成功, v7 列取值 True。其他行由于匹配失败,所以 v7列取值 False。
step2:selection 阶段
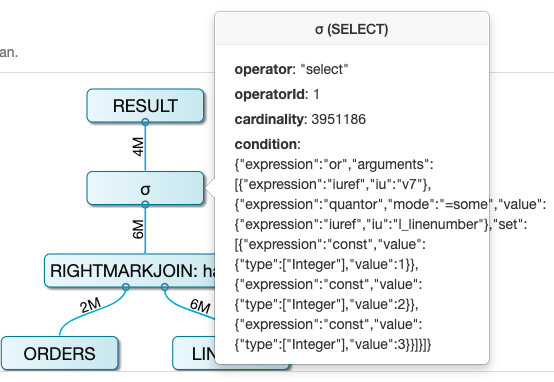
经过 Mark Join 算子后,在往上看 Query Plan 进入 selection 阶段,对 Mark Join 输出的 tuple 进行过滤。条件为:
v7 = true or l_linenumber in (1,2,3)
等价于
where exists (select * from orders
where o_orderkey = l_orderkey)
or l_linenumber in (1,2,3); 满足 v7 列为true 的或者满足 l_linenumber 在 1,2,3 这三个取值的行都可以被输出。其实就是将满足子查询条件的行,或者满足 in 表达式的行都会被保留。这样就等同于完成了原本 where 语句的过滤语义。

从表中我们可以看到,虽然第二行数据并不能满足 exists 条件,但是因为他的 linenumber 取值在 (1,2,3) 范围内,所以也可以被输出。
step3:projection 阶段
经过 selection 算子,整个查询最后再进行一次 projection ,保留列 l_orderkey 就完成了。
至此,Mark Join 算子完美的支持了,将一个 nested subquery 转换成了非嵌套的 query,同时还能保留 where 条件中的 disjunction 的逻辑。
实现算法
我们现在已经知道了 Mark Join 的主要功能就是在 Join 的同时,产生一个新的 marker 列,并且将 Join 的结果存储在这个 marker 列中。那么下面就用算法具体解释一下 Mark Join 是如何产生这个新的列,并且如何给这个新的列取值的。 在真实场景中,实际上 Marker 列的取值有三种:
- True:当 join 条件满足时
- False:当 join 条件不满足时
- Null:当 join 的列存在 Null 取值,且和其他列取值比较还不为 True 的时候。
其中 True 和 False 都很好理解,Null 则是一种需要被特殊处理的情况。用 Left Mark Join 举例来说,当你的右表中存在 Null 取值时,尽管左表取值可能无法匹配右表中的任何取值,但是和 Null 匹配时,就会产生 Null 这种取值。
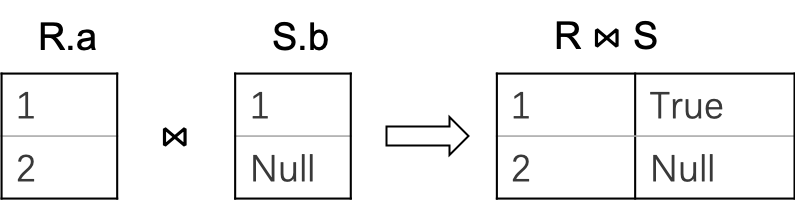
上图中我们可以看到,虽然 R.a 取值为 2 时,无法匹配到 S.b 的值,但是由于 S.b 中存在取值 Null, 2 = Null 匹配出的结果为 Null ,所以 marker 列被标记为 Null。
尽管我们知道 Null 这个取值在 distjunctive Where 子句中其实和 False 的含义完全一样。但是我们依旧需要保留 Null 取值,因为在其他语句中 Null 还是有意义的。比如 select k1 in (subquery) from table。
下面我们进入完整的算法实现:
for each r in R
if r.a is NULL
mark r as NULL
store r into H["null"]
else
mark r as FALSE
a' = r.a cast to compare type
if cast was exact
store r into H[a']
else
store r into H["extra"]
hadNull = false
for each s in S
if s.b is NULL
hadNull = true
else
b' = s.b cast to compare type
if cast was exact
for each r in H[b']
if r.a = s.b
mark r as TRUE
if |S| = 0
mark all entries in H["null"] as FALSE
for each r in H
if r is marked FALSE and hadNull
mark r as NULL
emit r,marker of rR 是左孩子,S 是右孩子,join 的条件是 R.a = S.b。
step1:左孩子
for each r in R,先处理左孩子,如果左孩子取值为 Null,此时无论右孩子取值为什么,他均为 Null,所以标记 marker 列为 Null。并且用 H[“null”] 数组将这些取值为 Null 的行存储起来。如果左孩子取值不为 Null,则先默认将 marker 都标记为 False,待后面进行处理,并存储在 H[a’] 或者 H[“extra”] 中。
step2:右孩子
for each s in S,处理右孩子,当右孩子取值存在 Null 的时候,则进行 hadNull 标记。由于右孩子如果存在 Null 则所有无法 Match 上的 marker 取值都需要重新标记为 Null,所以这里记录一下以便后面进行处理。如果右孩子取值不为 Null ,则看他是否能满足 r.a = s.b 的条件,满足则将 marker 标记为 True。
step 2 完成后会有三种情况
- 满足 r.a = s.b 条件的列被直接标记为 True,
- Null 列未标记,
- 其他列则标记为 False。
step3:调整 Null 取值
这时候我们就需要考虑左右值为 Null 的情况,并将一些错误的 False 修改为 null。
-
比如当右孩子为空集时
if |S| = 0,则左孩子所有的 Null 列直接被标记为 False。这时候左孩子的取值实际只有一种 False。 -
当右孩子存在 Null 值,且左孩子被标记为 False。
if r is marked FALSE and hadNull则需要把这些取值为 False 的 marker 改为 Null。也就是说,当右孩子存在 Null 值时,marker 值要么是 True 要么是 Null。
step4:输出
最后再把 r 行和 marker 列一起输出即可。
一些细节
Hyper 的论文中,并没有描述 Mark Join 的物理实现,比如左表和右表进行 mark join 的时候是否也是使用的Hash Table。这里根据规划中的 RightMarkJoin:Hash 可以猜测,exists 等值的 Join 应该是使用的 Hash Table。也就是说, Mark Join 算子在实现的时候也是通过 Hash Table 去进行 join 条件的判断的。
Mark Join 还分为 Left Mark Join 和 Right Mark Join,这两者的本质区别是,mark 左表还是 mark 右表。
其他用法
Mark Join 其实除了 disjunctive where 子句这种场景,还有很多其他的使用场景。 比如 select 语句中的子查询。
select Title, ECTS = any (select ECTS from Courses c2
where Lecturer = 123) someEqual
from Courses c1
这个语句就可以直接改写成下面的 mark join:
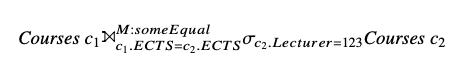
取C2中 Lecturer = 123 和 C1 进行 Mark Join 条件为 c1.ETCS = c2. ETCS 并且将结果存储在 someEqual 列中。someEqual 列的取值有三种,True,False 和 Null。
至此,Mark Join 的介绍完毕。但实际上解决这类子查询的方式并不是只有 Mark Join 这一种,Greemplum 就使用 outer join 的方式解决了这类查询(并且规避了 Join 膨胀的问题)其不同系统实现的对比会在之后的文章中讨论。
如有引用,请邮件联系,并在允许情况下,注明来源~